For years, data-driven tech companies have used customers as their raw material: Facebook, Google, Amazon, and others track our moves across the web in order to sell that information and target advertisements. For a long time, users found this an acceptable tradeoff- but in the wake of the 2016 election and amidst the changes brought about by the General Data Protection Regulation (GDPR), users are changing their attitudes.
What if users could own their data and can choose to share aspects of it in return for specific services? GDPR requires that users see what data gets collected, and limits the ability of companies to reuse that data- but still means that Facebook can have access to our internet breadcrumbs and all the valuable data we generate.
The conventional model of machine learning, where all data generated by the user is owned by private companies, who can use it to influence the user’s actions.
Instead, imagine if users could instantly flip off outside access to sensitive information, without battling with the tech giants. This idea, championed by Andreas Weigend in Data for the People, is alluring but has previously been impossible to implement. New developments in applied mathematics around cryptography, blockchains, and machine learning can change that, allowing for a new world of data-as-a-service business models.

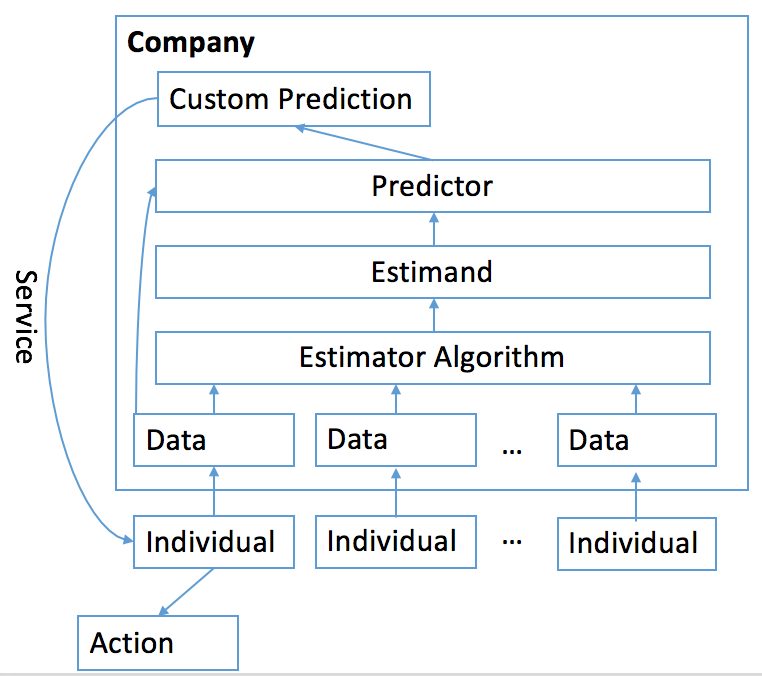
A privacy-preserving model for machine learning and data services. Users control their data, interacting with companies through privacy-preserving APIs which can be used to selectively provide data (e.g. training a machine learning estimator) or request an estimate (e.g. getting a prediction)
Technical tools
The tools for realizing this dream have slowly coalesced over the last ten years. This section outlines the key aspects of a trustless, anonymous platform for machine learning, artificial intelligence, and consensus-based problem solving:
- Aggregation: Secure Multi-Party Computation. This technique allows computations to be done with multiple data streams, without leaking information about any of the underlying data. This is useful for aggregating inputs from multiple users, into an anonymous update.
- Computation: Zero-Knowledge Proofs. These can prove that local computations are being done correctly, without sharing the details of the computation: this allows
- Origination: Blockchains. These can be used to guarantee that data is genuine and not falsified, even when the data is opaque to the outside world.
Other relevant tools include smart contracts (code on a blockchain to guarantee execution), Tor-like protocols (privacy-preserving data sharing), and hash trees (succinctly guaranteeing the accuracy of data without sharing its contents).
Pieces of these are already implemented in industry: Federated machine learning environments (most actively researched by Google) utilize secure multi-party computation to aggregate user data. Zero-knowledge proofs are being used to secure cryptocurrencies and some smart contracts. Blockchains have been used as a proof-of-existence registry for several years.
Composing these tools in different ways can create a variety of architectures for solving consensus problems, teaching machine learning algorithms, or providing customized services. It also paves the way for privacy-preserving APIs, in which users can get paid to help train machine learning tools, or pay for customized services- all without revealing an iota of data.
Imagine sharing genetic data to improve disease identification and treatment- without revealing your identity. Or getting a customized recommendation when buying a pair of shoes- but not letting the vendor see your shopping history. Even apply for a mortgage- without revealing anything to a credit bureau.
The challenges to implementing these are in making them scalable to large problems, secure against attacks, and robust to seldom-connected devices.